Em uma das reuniões dessa última semana na empresa onde trabalho surgiu uma necessidade simples de comunicação: Precisamos que toda a equipe saiba quando um novo release de algum dos nossos repositórios for criado no Github.
Como usamos o Slack como ferramenta de comunicação interna, na hora já pensei:
“Esta é a minha chance de criar um bot para o Slack!”
Sempre tive vontade de fazer algo para o Slack, mas não tinha conseguido achar um tempo e nem um motivo específico para isso. Eu já imaginava que para esse objetivo, avisar sobre um novo release, não seria algo complicado.
Realmente não foi. Em apenas algumas linhas deu pra criar um bot que conecta os webhooks do Github e do Slack utilizando o Flask como meio-campo.
Abaixo o código final da primeira versão.
# coding: utf-8
import os
import requests
from flask import Flask
from flask import request
app = Flask(__name__)
slack_webhook_url = os.getenv('SLACK_WEBHOOK_URL')
@app.route("/", methods=['POST', ])
def webhook():
action = request.json['action']
release = request.json['release']
repository = request.json['repository']
slack_data = {
"text": "A new release from *{repo_name}* was {action}!\n"
"Click <{release_url}|Release {tag_name}> for more details".format(action=action,
repo_name=repository['name'],
release_url=release['url'],
tag_name=release['tag_name'])
}
response = requests.post(slack_webhook_url, json=slack_data)
if response.status_code != 200:
raise ValueError(
'Request to slack returned an error {}, the response is:\n{}'.format(response.status_code,
response.text)
)
return ""
Pelo pouco tempo que passei lendo sobre como fazer um bot para o Slack eu entendi que você cadastra um Incoming Webhook e eles geram uma URL a qual você irá executar um request do tipo POST enviando a mensagem que você quer que um canal específico receba.
É realmente muito simples, porque a própria URL já carrega os tokens que são gerados para você.
Existem diversas outras funcionalidades que podem ser criadas em um bot para o Slack e a documentação deles cobre tudo. Mas vou falar apenas desse pequeno release-alert que criei.
Explicando linha por linha
Antes de começar a escrever o código vou precisar do Flask e de alguns outros pacotes. Então começo ainda na linha de comando do shell.
$ pip install Flask
$ pip install requests
Depois eu coloco a URL que gerei no Incoming Webhooks do Slack em uma variável de ambiente que chamo de SLACK_WEBHOOK_URL. Depois basta importá-la para dentro do código.
$ export SLACK_WEBHOOK_URL=<aqui vai a url do webhook do slack>
Agora crio meu arquivo Python chamado bot.py. Como estou usando o Flask, só vou precisar desse arquivo e praticamente nada mais.
Nas primeiras linhas começo importando o que vou utilizar e criando o app do Flask.
import os
import requests
from flask import Flask
from flask import request
app = Flask(__name__)
Trago para dentro do código a variável de ambiente que criei antes.
Agora vou começar a montar o meu endpoint. Ele receberá um evento POST enviado pelo webhook do Github. Para que isso aconteça você precisa cadastrar uma URL de webhook no settings do seu projeto no Github.
No meu caso, eu cadastrei a webhook no settings da organização, já que queria que todos os projetos da empresa disparassem o aviso. Mas funciona do mesmo jeito em qualquer um dos casos.
Quando cadastrei o meu webhook no Github especifiquei que gostaria de receber apenas os eventos relacionados ao release dos projetos.
Para testar o código localmente eu utilizei o ngrok. Explico como usar o ngrok em outra publicação.
O Flask facilita recuperar informações de um corpo de um request JSON com o seu objeto request nativo. Basta chamar request.json e ele retorna um dicionário.
Agora eu vou montar o corpo da mensagem que enviarei para o Slack. O formato pedido é muito simples: um JSON com um campo ‘text’.
slack_data = {
"text": "A new release from *{repo_name}* was {action}!\n"
"Click <{release_url}|Release {tag_name}> for more details".format(action=action,
repo_name=repository['name'],
release_url=release['url'],
tag_name=release['tag_name'])
}
Esse dicionário será transformado em um JSON pela próxima linha. O pacote requests já resolve isso para mim através do argumento json.
response = requests.post(slack_webhook_url, json=slack_data)
if response.status_code != 200:
raise ValueError(
'Request to slack returned an error {}, the response is:\n{}'.format(response.status_code,
response.text)
)
return ""
No final do arquivo estou apenas tratando algum possível erro. Caso o requests retorne um status_code diferente de 200 eu levanto uma exceção.
No final retorno uma string vazia, porque cada endpoint do Flask precisa retornar alguma coisa para não levantar erros.
Para que meu bot fique disponível o tempo todo, fiz um deploy na minha conta gratuita do Heroku. E voilá!
Este é um tutorial no estilo passo-a-passo para a criação de um chatbot simples para o Facebook Messenger. Ele foi escrito como conteúdo para uma pequena apresentação que farei em um evento interno de compartilhamento de conhecimento da TIKAL TECH, empresa em que trabalho.
Existem diversas maneiras de se criar um bot para o Messenger, mas neste tutorial eu utilizarei apenas o microframework para web escrito em Python chamado Flask e nada mais.
Esse tutorial resume algumas das coisas que aprendi durante o desenvolvimento de um outro projeto.
Passo 1
Criando um aplicativo e vinculando com uma fanpage
Acesse o dashboard do Facebook Developers e crie um aplicativo. No tipo de aplicativo escolha “Aplicativos para o Facebook Messenger”. Se você não tiver uma página para vincular o aplicativo, crie uma também.
Com a página criada, entre novamente no dashboard e gere um token para o aplicativo ser vinculado à página.
Passo 2
Começando a programar o backend
Vamos utilizar o microframework Flask para facilitar esse desenvolvimento, mas qualquer outro framework web pode ser utilizado.
Se você está acostumado a trabalhar com Python você pode pular alguns dos passos abaixo.
Vamos começar criando um ambiente virtual na linha de comando e instalando o Flask, o requests e o gunicorn. Precisaremos dos dois primeiros para nosso chatbot e o último será para o deploy.
Escolha o diretório que você vai utilizar e digite os seguintes comandos.
Agora temos um arquivo index.py no nosso diretório chatbot. É nele que faremos os próximos passos do nosso tutorial.
Começamos com o básico do Flask.
import os
from flask import Flask, request
token = os.environ.get('FB_ACCESS_TOKEN')
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def webhook():
return 'Nothing'
if __name__ == '__main__':
app.run(debug=True)
Esse arquivo tem o básico do que precisamos para rodar um app no Flask.
O token que estamos pegando de uma variável de ambiente é o token que geramos no dashboard do Facebook.
Para adicioná-lo como variável de ambiente execute na linha de comando:
$ export FB_ACCESS_TOKEN=<cole o token gerado>
Passo 3
Configurando os Webhooks
Temos que configurar um webhook para que o Facebook saiba para onde enviar as requisições do chat.
Para isso utilizaremos o ngrok para “tunelar” nosso localhost. Para saber como funciona, veja esta publicação.
Vamos rodar nosso servidor local com o Flask. Na linha de comando com o virtualenv ativado, digite:
(chatbot)$ python index.py
Abra outra janela de terminal para iniciar o ngrok.
./ngrok http 5000
Agora temos um endereço web com HTTPS para cadastrar no dashboard do Facebook. Basta ir até o painel Webhooks e clicar em Configurar Webhooks.
Antes de cadastrar o endereço, é preciso adicionar uma parte a mais no nosso index.py. O bloco em negrito tem o que é preciso para que o Facebook aceite esse link como elegível para webhook.
def webhook():
if request.method == 'POST':
pass
elif request.method == 'GET': # Para a verificação inicial
if request.args.get('hub.verify_token') == os.environ.get('FB_VERIFY_TOKEN'):
return request.args.get('hub.challenge')
return "Wrong Verify Token"
return "Nothing"
Coloque o endereço gerado pelo ngrok, por exemplo https://7f3o6bd7.ngrok.io, e crie uma frase de segurança. Essa frase colocamos na variável de ambiente FB_VERIFY_TOKEN que você pode ver no código acima.
(chatbot)$ export FB_VERIFY_TOKEN=<digite qualquer frase aqui>
Com isso já somos capazes de registrar nosso endereço do chatbot no Facebook.
Para finalizar, no mesmo painel de webhooks você deve “inscrever” sua página criada ao webhook adicionado. Essa parte é bem autoexplicativa.
Passo 4
Lendo a mensagem e respondendo
Agora vamos adicionar uma maneira de lermos o que o usuário nos enviou pelo Messenger. Isso é feito verificando os dados enviados na requisição que o chat nos envia via POST.
Então vamos adicionar ao nosso código o seguinte trecho:
import os
import requests
import traceback
import json
(...)
def webhook():
if request.method == 'POST':
try:
data = json.loads(request.data.decode())
text = data['entry'][0]['messaging'][0]['message']['text']
sender = data['entry'][0]['messaging'][0]['sender']['id']
payload = {'recipient': {'id': sender}, 'message': {'text': "Hello World"}}
r = requests.post('https://graph.facebook.com/v2.6/me/messages/?access_token=' + token, json=payload)
except Exception as e:
print(traceback.format_exc())
elif request.method == 'GET': # Para a verificação inicial
(...)
Explicando o que estamos fazendo. Adicionamos os imports necessários no topo do arquivo index.py e dentro do nosso método webhook verificamos se a requisição chegou como POST.
Com o data = json.loads(request.data.decode()) nós capturamos o corpo da mensagem que nos foi enviado pelo Messenger.
Com o trecho text = data['entry'][0]['messaging'][0]['message']['text']conseguimos pegar o texto que o usuário enviou via chat.
Pra saber quem enviou, usamos o trecho sender = data['entry'][0]['messaging'][0]['sender']['id']. Essa informação é necessária para que possamos enviar uma resposta para o usuário correto.
No trecho payload = {'recipient': {'id': sender}, 'message': {'text: "Hello World"}} nós montamos o corpo da nossa resposta ao usuário.
Para finalizar, respondemos enviando uma requisição para o endereço da API do Facebook Messenger com o corpo criado anteriormente. O trecho referente ao envio segue abaixo.
r = requests.post('https://graph.facebook.com/v2.6/me/messages/?access_token=' + token, json=payload)
Colocamos tudo isso dentro de um try/except para capturar um possível erro que imprimiremos no console. Isso fazemos com o trecho final do código que acabamos de adicionar.
except Exception as e:
print(traceback.format_exc())
Com isso, respondemos um Hello World para cada entrada que o usuário nos enviar.
Passo 5
Tornando o chatbot em algo útil
Como responder Hello World para cada mensagem é algo totalmente inútil para um bot fazer, vamos colocar uma funcionalidade aproveitando a documentação do Messenger, que é bem completa.
Vamos pegar a localização do usuário e enviar informações sobre o clima atual em sua localidade.
Primeiro criamos uma função que monta um payload com formatoQuick Reply do Messenger. O formato que precisamos enviar para ter esse resultado é facilmente encontrado na documentação do Messenger. Nela definiremos que queremos um tipo location.
Agora, quando formos enviar uma mensagem para nosso usuário, utilizamos essa função no lugar do antigo payload.
payload = location_quick_reply(sender)
Isso vai enviar uma opção para o usuário nos enviar sua localização. Como mostra a imagem abaixo.
Vamos receber essa localização de maneira diferente do que um texto comum, ela virá como um anexo. Dessa forma mudamos nossa verificação de texto para o bloco abaixo.
if request.method == 'POST':
try:
data = json.loads(request.data.decode())
print(data)
message = data['entry'][0]['messaging'][0]['message']
sender = data['entry'][0]['messaging'][0]['sender']['id'] # Sender ID
if 'attachments' in message:
if 'payload' in message['attachments'][0]:
if 'coordinates' in message['attachments'][0]['payload']:
location = message['attachments'][0]['payload']['coordinates']
latitude = location['lat']
longitude = location['long']
else:
text = message['text']
payload = location_quick_reply(sender)
r = requests.post('https://graph.facebook.com/v2.6/me/messages/?access_token=' + token,
json=payload)
Nesse bloco verificamos se o corpo da requisição que o Messenger nos enviou possui uma chave attachments e se possui uma chave payload com as coordenadas da localização.
Se não vier nesse formato é porque ele enviou uma mensagem normal de texto, então reenviamos o botão que pede sua localização.
Agora que pegamos a latitude e longitude, podemos utilizar uma API aberta de clima para enviar as informações para nosso usuário.
Eu escolhi a OpenWeatherMap para isso. Basta se inscrever e gerar uma chave de API no site deles e você já pode começar a fazer requisições variadas para receber informações de clima do mundo inteiro.
Adicionei a chave de API deles numa variável de ambiente para utilizar nas requisições que farei dentro do código e pronto.
(chatbot)$ export WEATHER_API_KEY=<digite a api key>
Agora podemos acessar o endpoint que eles fornecem para current weathere pegar a temperatura e outros dados climáticos do local do usuário.
Logo após o trecho do código onde pegamos a latitude e longitude, adicionamos uma requisição para a API do OpenWeatherMap para montar a resposta que daremos ao nosso usuário.
Basicamente analisei a resposta da API do OpenWeatherMap e peguei as informações que gostaria de exibir ao usuário. Depois disso montei um bloco de texto simples exibindo algumas das informações.
Pronto! Agora temos uma funcionalidade para nosso bot experimental.
Passo 6
Fazendo o deploy
Vamos colocar nosso novo bot em um servidor para que ele fique disponível constantemente. Como eu falei anteriormente é preciso uma conexão segura (HTTPS) para que o Facebook aceite a URL do chatbot.
Com o Heroku é muito simples fazer o deploy. Basta que o seu código esteja no github, por exemplo, e com um clique ele fica online.
Para fazê-lo funcionar no Heroku é preciso adicionar dois novos arquivos ao nosso projeto. O Procfile e o runtime.txt. O primeiro configura o servidor web e o segundo define que estamos usando o Python 3.
Se você estiver utilizando a versão 2 do Python, o segundo arquivo é desnecessário.
O arquivo Procfile ficará assim:
web: gunicorn index:app
E o runtime.txt assim:
python-3.5.2
Criamos uma conta no Heroku e adicionamos um novo app. Em seguida vamos na aba Deploy e conectamos com o Github. Com isso basta escolher o seu repositório e clicar em Deploy Branch.
Abas do Dashboard do Heroku
Precisamos adicionar nossas variáveis de ambiente. Para isso devemos ir à aba Settings e adicionar manualmente por lá. É simples e autoexplicativo.
Agora testamos nossa URL, que será algo como https://<nome_do_app>.herokuapp.com.
Voltamos ao dashboard de developers do Facebook para mudar nosso webhook configurado. Lembra que fizemos isso com o endereço que o ngrok nos forneceu no passo três? Agora vamos mudar a URL para a nova que o Heroku nos forneceu.
Aprovação do Facebook
Com nosso bot funcional e online, agora temos que deixá-lo em aprovação no dashboard de developers do Facebook.
Basta preencher o que eles pedem por lá e aguardar até cinco dias para que seu bot possa ser usado por qualquer usuário do Facebook.
Conclusão
O Facebook aprovou rapidamente o chatbot que chamei de Climão. Isso porque utilizamos apenas a permissão de messages do Webhook, que é a mais simples.
Para utilizar esse bot acesse a Página do Facebook e envie uma mensagem para o Climão. =)
O código que criamos durante esse tutorial está disponível no Github.
Qualquer dúvida, entre em contato pelas respostas abaixo.
Olhar para trás é sempre positivo. Nos ajuda a entender o que deu certo e o que deu errado em nossas vidas. É por isso que eu gosto de parar para fazer uma retrospectiva pessoal no final de cada ano.
Ah, 2016! Um ano que muitos falam que foi horrível, que só aconteceu coisa ruim e que só querem que acabe logo.
Não dá pra negar que muita coisa ruim aconteceu de um modo geral nesse ano que está acabando. Até me sinto mal dizendo que para mim foi um ano positivo.
Um ano de reconstrução pessoal. Um ano em que as coisas começaram a encaixar em seus devidos lugares. Um ano de autoconhecimento, mais uma vez, e com algumas dificuldades, mas nada comparado a tudo que aconteceu comigo em 2015.
Como tudo é uma questão de contexto, posso dizer que depois de 2015 vai ser difícil falar que um ano realmente me ensinou tanto através de acontecimentos não tão bons assim. Mas também aprendi muito com 2016.
Portanto, 2016 foi um bom ano sim… pelo menos para mim.
No trabalho consegui me estabilizar após o lançamento de dois produtos nos quais eu tive uma grande participação no desenvolvimento. O Diligeiro, lançado ainda na primeira metade do ano, e o SEUPROCESSO, lançado neste final de ano.
Com o primeiro eu aprendi muito no desenvolvimento de API Rest com Python, aprendi como trabalhar com GIS (Geolocalização) e também acabei me aventurando no desenvolvimento de webapp utilizando o AngularJS. Todos os três eram novidades para mim naquele momento, mas hoje, graças à essa experiência, eu posso dizer que consigo ter domínio em cada um deles.
Já com o SEUPROCESSO a coisa foi diferente. Trabalhamos em um ritmo muito intenso para transformar um sistema que já funcionava em uma API Rest e um webapp em tempo recorde. Fortaleci ainda mais os meus conhecimentos com esses dois, mas não foi um processo onde tive tempo para “aprender” mais.
Falando sobre o que aprendi, escrevi publicações sobre o desenvolvimento de APIs e sobre GIS com Django.
Aos poucos fui deixando de lado os trabalhos extras, os famosos freelas, para achar um tempo para a vida pessoal voltar à cena. Para isso, foi preciso organizar as contas de vez. Tarefa que ainda está em andamento…
Tenho certeza de que não sou o único que ainda está tentando organizar a vida financeira, infelizmente nosso país vem sofrendo com esse momento complicado da economia e da política. Então, não vou ficar reclamando sobre essa parte…
Como sobrou um pouco mais de tempo sem os freelas, comecei a estudar um pouco sobre outras coisas legais para fazer na minha área. E, mais ou menos na metade do ano, resolvi começar um desafio pessoal: fazer um chatbot.
Durante o ano li muito a respeito dos chatbots e quis criar um completo como aprendizado. Essa tarefa está quase concluída e já tem uma publicação quase pronta com o diário de desenvolvimento desse desafio… Pode ser que ela acabe publicada ainda esse ano por aqui.
Para finalizar, que tal lembrar do que não deu certo também?
Em uma meta eu falhei miseravelmente em 2016. Encontrar algo relacionado à atividade física que me prendesse de vez, como já aconteceu no passado com a arte marcial. Experimentei diversos tipos de atividades, mas infelizmente ainda não encontrei uma que tenha me conquistado pra valer.
Tenho a necessidade de melhorar minha saúde para que eu ainda possa escrever muitas retrospectivas no futuro. E sei que exercício físico é vital para isso. Portanto não vou desistir ainda.
Resumindo, 2016 foi ano de trabalhar muito e de ajustar a vida para que 2017 venha trazer os frutos desse trabalho e desse esforço para aparar as arestas.
Veja como expor seu servidor local para a internet e para que serve isso
O tunelamento do localhost é uma maneira de ter um “link externo” que aponte para alguma aplicação que você esteja rodando localmente. Dessa forma podemos “expor” nosso servidor local de forma segura.
Mas por que eu iria querer isso? Podemos usar essa solução para diversas situações, principalmente no desenvolvimento web. Vou mostrar alguns exemplos de uso nessa publicação.
Para os exemplos a seguir eu estou usando o ngrok, um software que facilita muito isso e ainda mantém essa exposição totalmente segura.
Mostrar um desenvolvimento em andamento para o cliente
Digamos que você esteja desenvolvendo um site ou um sistema web para um cliente e quer mostrar o que você desenvolveu até o momento. O mais comum seria fazer o deploy do trabalho em andamento em um servidor web e disponibilizar o link para seu cliente.
Mas existe uma outra opção, podemos deixar o site rodando localmente e tunelar com o ngrok.
Você pode iniciar um servidor local com o SimpleHTTPServer do Python, por exemplo, e rodar o ngrok na linha de comando, como no exemplo abaixo.
$ python -m SimpleHTTPServer 8000
Serving HTTP on 0.0.0.0 port 8000 ...
Em outra aba do terminal você inicia o tunelamento.
./ngrok http 8000
Agora ele irá exibir o endereço que ficará disponível para seu cliente pela internet. Será algo como http://36096fff.ngrok.io.
Ao rodar, o ngrok vai aparecer assim no seu terminal…
Estamos iniciando um servidor HTTP local na porta 8000. Perceba que o comando de tunelamento recebeu os parâmetros http e 8000, indicando que é um servidor http e que está usando a porta 8000.
Testar um chatbot durante o desenvolvimento
Durante o desenvolvimento de um chatbot para o Facebook Messenger, por exemplo, não é possível testar sem um “endereço web”. É preciso que seja registrada uma URL nas configurações do seu chatbot do Messenger para que ele receba os eventos de mensagem.
Para entender melhor sobre isso, veja este artigo.
Para que você não precise fazer deploy de cada pequena alteração em um servidor web para testar no seu chatbot, crie um tunelamento, como no exemplo anterior, e registre o endereço gerado na seção webhook nas configurações do chatbot no Messenger.
Obs: Nem todos os aplicativos de mensagem se utilizam de webhooks para receber os eventos. No caso do Telegram, como neste link, não é necessário utilizar o tunelamento.
Testar endpoints de webhooks
Eu falei em webhooks no item anterior. Pra quem não sabe o que é, segue uma tradução livre de uma parte do artigo da Wikipedia:
Webhooks são “retornos de chamada HTTP definidos pelo usuário”. Normalmente eles são ativados por algum evento, como o push de código para um repositório ou um novo comentário postado em um blog. Quando ele acontece, o site origem faz uma requisição HTTP para a URI configurada para o webhook, enviando os dados do evento.
Existem diversos serviços que utilizam esse formato para enviar dados de eventos. Um bom exemplo é o Sendgrid ou o Mandrill, que usam webhooks para enviar os eventos de email (lido, marcado como spam, link clicado, etc.) para um sistema de terceiros que esteja usando sua API.
Outro bom exemplo são integrações com gateways de pagamento, como Iugu, PagSeguro ou PayPal, onde, mesmo durante o desenvolvimento, você precisa de um “endereço web aberto” para receber os eventos relacionados aos pagamentos, alterando o status de uma compra, por exemplo.
Para isso, abra um tunelamento com o ngrok e registre o novo endereço gerado por ele com o seu endpoint para receber os eventos webhook do serviço que você está utilizando.
Painel do ngrok
Uma funcionalidade interessante do ngrok é o seu painel, ou interface web.
Screenshot da interface web
Com ela você vê todas as requisições que foram feitas ao seu endereço web aberto. Com isso você pode verificar os dados que estão vindo com as requisições e ainda dar um “replay” na mesma, para testar novamente.
Para acessar, veja o endereço listado no terminal do ngrok como Web Interface e abra no seu navegador. Vai ser algo como http://127.0.0.1:4040.
Concluindo
Esses são alguns casos de uso para o tunelamento de localhost. Alguns deles eu já utilizei, como o teste de webhooks e a demonstração de desenvolvimento em andamento para cliente. Mas eu descobri mesmo que isso era possível ao ler um tutorial de criação de chatbot para o Facebook Messenger, então resolvi dar esse exemplo também.
Essa publicação é baseada na minha primeira experiência criando um chatbot para o Telegram usando Python. O código fonte dessa experiência pode ser encontrado no meu Github.
The Botfather
O Telegram facilita muito a criação de bots para seu sistema. Além de uma documentação muito boa e uma API muito simples de usar, ele possui o BotFather, um bot que ajuda qualquer um a criar seu próprio bot.
Segundo a documentação do Telegram:
BotFather is the one bot to rule them all. It will help you create new bots and change settings for existing ones.
Então vamos lá. Para começar é preciso acessar o @BotFather e fazer o registro do seu novo chatbot.
Para qualquer criação ou configuração de bot é preciso acessá-lo. E como vamos criar um novo bot, acessamos o link @BotFather.
Lá você terá acesso a diversos comandos, dentre eles o /start, que irá apresentar a lista desses comandos e o /newbot, que serve para a criação de um novo bot.
Quando executarmos o /newbot ele pede algumas configurações, como o nome e o username que serão utilizados pelo bot. Nada complicado.
Seu bot será como um usuário comum do Telegram, com um “nome para exibição” e um “nome de usuário” (username) para controle.
Assim que forem preenchidos os dados necessários ele irá gerar um token para ser utilizado no seu script. Esse token é único e serve como uma “senha” para seu bot, portanto deve ser mantido em sigilo.
Para saber mais sobre o @BotFather, acesse a documentação do Telegram que fala sobre bots para desenvolvedores.
Armazenando e acessando o token
Agora que já temos o token do nosso bot, devemos guardá-lo em uma variável de ambiente para que possamos acessá-lo posteriormente no nosso script Python.
Na linha de comando, execute o seguinte:
$ export BOT_API_TOKEN="<aqui vai o token gerado pelo botfather>"
Agora você poderá recuperá-lo facilmente em seu script Python com apenas duas linhas de código.
import os
token = os.environ['BOT_API_TOKEN']
Obs: Esta é apenas uma sugestão de como armazenar essa informação. Você pode guardar seu token da maneira que achar melhor.
Implementando os comandos
Um pacote que facilita muito a vida de quem está desenvolvendo um bot para o Telegram é o pyTelegramBotAPI. Com ele basta adicionar decorators nas suas funções e elas passarão a atender aos comandos recebidos.
Podemos usar o seguinte comando para instalar o pacote via pip:
$ pip install pyTelegramBotAPI
Agora chegou a hora de implementar os comandos que controlarão o bot.
Vou abordar somente um tipo de decorator e de resposta a caráter de exemplo. Através da documentação do pyTelegramBotAPI você consegue facilmente implementar diversas outras formas de input e output para o seu bot.
Começamos o script em Python fazendo nossos imports e iniciando o telebot com o token do Telegram gerado pelo @BotFather, como no exemplo de código abaixo.
import os
import telebot
bot = telebot.TeleBot(os.environ['BOT_API_TOKEN'])
Agora é só começar a implementar os comandos. No exemplo abaixo eu estou implementando uma mensagem de boas vindas para os comandos /start e /help.
@bot.message_handler(commands=['start', 'help'])
def send_welcome(message):
bot.reply_to(message, u"Olá, bem-vindo ao bot!")
No final do script adicionamos o método bot.polling() para inicializar o nosso novíssimo bot.
bot.polling()
Basta executar o script em linha de comando e o seu bot está pronto para começar a ser testado.
$ python bot.py
Para executar o teste, basta acessar seu Telegram e seguir o usuário com o username que você deu para seu bot lá no começo do processo, com o @BotFather.
E voilá!
Simples, não é? Veja como nosso script em Python ficou bem pequeno.
import os
import telebot
bot = telebot.TeleBot(os.environ['BOT_API_TOKEN'])
@bot.message_handler(commands=['start', 'help'])
def send_welcome(message):
bot.reply_to(message, u"Olá, bem-vindo ao bot!")
Na área de desenvolvimento de software sempre somos bombardeados por notícias de novas tecnologias que estão dominando o mercado. E que, para ficar na “crista da onda” (e ser bem pago), é preciso trabalhar com essa ou aquela nova tecnologia.
Essa é a hora que o desespero bate e você pensa:
“Tenho que aprender esse novo framework senão vou ficar para trás!”
Tenho certeza que isso já aconteceu com muitos programadores por aí.
Aí é só aprender que ficará tudo bem, certo? Mas não é tão simples assim.
Para aprender uma coisa pra valer não basta seguir aquele tutorial maneiro do blog do especialista. Envolve muito mais do que isso.
Aprendendo Python
Em 2012 eu fiz minhas primeiras tentativas de aprender Python e Django, porque eu achava que o PHP não me daria futuro. Leia-se grana.
Em 2012 eu achava que Python me deixaria assim… Doce ilusão.
Objetivo bobo para aprender algo, na verdade. Em 2010 eu tinha tentado a mesma coisa com Java… Não rolou.
Eu fiz uns projetos pessoais como um portfólio e um controle financeiro seguindo alguns tutoriais e a documentação do Django, mas somente a caráter de teste. Não cheguei nem a arranhar a superfície do que o Python ou o Django poderiam me proporcionar como soluções.
Não existia um problema real ao qual eu precisava do Python para resolver.
Eu continuava conseguindo trabalhos somente com PHP, por causa da minha experiência profissional. Com isso acabei não aprendendo nada relacionado a Python na época.
Como não gostar de Python, não é?
Depois de um bom tempo, eu continuava com PHP nas empresas em que trabalhava, mas não queria desistir do Python porque tinha gostado de programar na linguagem.
Aí o objetivo era outro. Aprender porque eu gostava. Mas como?
Foi então que resolvi fazer alguns projetos freelance com o Flask, outro framework em Python. A partir daí comecei a entender e a dominar um pouco mais essa linguagem.
Foi uma tática muito mais inteligente.
Depois de um tempo fazendo esses freelances, acabei conseguindo um emprego para desenvolvedor em Python e hoje trabalho diariamente com ele.
Não-aprendendo AngularJS
Outra experiência parecida foi com o desenvolvimento de frontend.
Durante um período em que fiquei desempregado, comecei a procurar vagas e percebi que existia muita procura por desenvolvedor frontend. Como sempre tive conhecimento sólido com HTML/CSS e JavaScript (e jQuery), pensei que poderia conseguir alguma coisa.
O problema é que a maioria das vagas exigia conhecimentos em AngularJS ou outro framework JavaScript. Me candidatei para várias delas e apesar de chegar à fase final de quase todas, não consegui ser contratado.
Eu tenho certeza que, mesmo tendo bom domínio de HTML/CSS/Javascript, não fui contratado porque não tinha familiaridade com nenhum dos (na época novos) frameworks de frontend.
Durante esse tempo eu fiz alguns tutoriais de AngularJS para tentar melhorar essa deficiência e até para fazer testes para algumas das vagas de emprego. Mas confesso que tudo me parecia meio confuso… No final não aprendi nada. Nem sequer entendi a base do framework.
Acabei por desistir na época.
Um tempo depois, precisei utilizar AngularJS em um projeto. Foi um tempo pesquisando para acabar entendendo e aprendendo. Hoje tenho um projeto em produção usando essa tecnologia.
Graças a necessidade.
Aprendendo com a necessidade
A verdade é que cada um tem seu jeito de fixar conhecimento. Não estou aqui para impor regras a algo tão subjetivo como a forma de aprendizagem de cada um.
Quero compartilhar a minha forma de aprender: E ela chama-se necessidade.
Eu só consigo aprender algo para valer se realmente usá-lo em algum projeto. Um projeto real.
Pode ser pessoal ou comercial, mas que seja algo que eu queira ou precise mesmo fazer.
Para que eu consiga entender e fixar é preciso existir a necessidade de resolver um problema com aquela tecnologia.
Foi assim com o Python, quando comecei a focar em projetos freelance com a linguagem, passei a aprendê-la de verdade.
Resumindo: se não existir um problema real para resolver, dificilmente se chega tão fundo a ponto de conhecer as verdadeiras funcionalidades e qualidades de certa tecnologia.
Quer aprender uma nova tecnologia?
Procure a tecnologia que dê a solução para um problema que você tenha que resolver, ela será a melhor e a mais fácil para você aprender.
O pessoal no escritório está se divertindo muito com o Cartola FC. Graças a Liga que criamos por lá, todos estamos envolvidos em escalar nossos times e para isso eu gosto de ver as probabilidades de resultado dos jogos. Descobri a pouco que o Bing faz uma previsão quando você busca por dois times que irão se enfrentar. Então resolvi automatizar essa busca para me divertir e experimentar o BeautifulSoup4 (BS) para fazer crawler.
A ideia de um crawler é pegar um HTML de um site e procurar informações dentro dele. O BeautfulSoup4 é quem faz o parse deste HTML e nos permite executar métodos que fazem essa busca por informações no mesmo.
Comecei fazendo um app de um arquivo só com o Flask apenas para executar os crawlers facilmente e exibir as informações e dentro dele criei dois métodos que executam crawlers. O primeiro atualiza a tabela de jogos com os resultados (e na primeira execução popula o banco com os jogos) e o segundo executa a busca no Bing e me retorna a previsão de resultado de cada jogo.
Então o primeiro passo é buscar esse HTML no site onde você tem a informação. No caso das informações dos jogos eu fui buscar no site tabeladobrasileirao.net.
Começo utilizando o requests do Python para retornar o HTML dos jogos e seus resultados (no caso dos que já aconteceram).
import requests
r = requests.get('http://www.tabeladobrasileirao.net/')
Depois é a vez do BeautifulSoup4 entrar em ação. Passo o resultado para o BS (com o encode) e ele “parseia” o HTML.
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text.encode('utf-8'), 'html.parser')
E aí começo a procurar. Depois de analisar o HTML do site, descubro onde as informações estão e uso o método find do BS para pegar as informações.
Neste código estou buscando a tabela com id igual a “jogos” e iterando sobre suas células, a partir das linhas da tabela. Como já identifiquei onde estão os dados, comecei a guardá-los em um dicionário (tratando datas, tipos e resultados nulos) que usarei para salvar no banco de dados posteriormente. Por exemplo, cada jogo está em uma linha e a data dele está na segunda coluna, então uso cells[1].find(text=true) para pegar somente o texto da célula.
Omiti a parte de salvar no banco de dados, mas o código todo está disponível no meu Github.
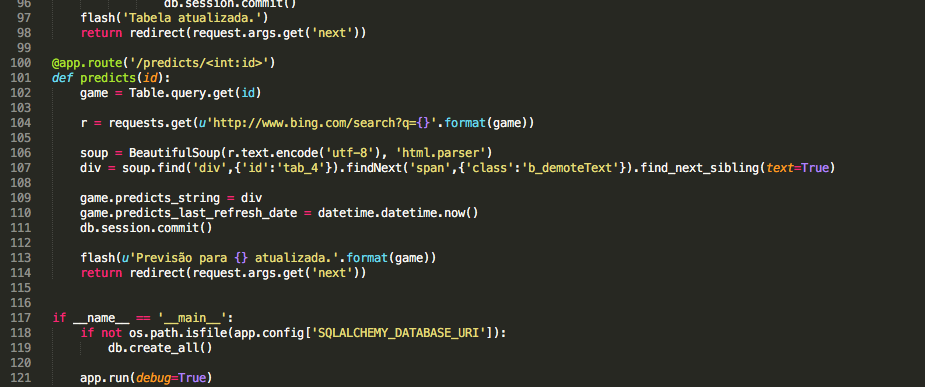
Com todos os jogos salvos é a vez de procurar pela previsão de resultados no Bing.
Mais uma vez começo com o requests e dou um parse no resultado com o BS. Leve em consideração que a variável “game” no código abaixo retorna a string com o jogo em questão, por exemplo, “Internacional x Grêmio” ou “Corinthians x Flamengo”.
r = requests.get(u'http://www.bing.com/search?q={}'.format(game))
soup = BeautifulSoup(r.text.encode('utf-8'), 'html.parser')
div = soup.find('div',{'id':'tab_4'}).findNext('span',{'class':'b_demoteText'}).find_next_sibling(text=True)
predicts_string = div
Nesse caso foi muito mais difícil achar o local exato no código fonte do resultado da busca do Bing do que foi no caso do tabeladobrasileirao.net. Mas com um pouco de pesquisa e muita tentativa e erro eu acabei chegando no texto de previsão do Bing usando soup.find(‘div’,{‘id’:’tab_4′}).findNext(‘span’,{‘class’:’b_demoteText’}).find_next_sibling(text=True), mais uma vez com text=true para retornar somente o texto do objeto que vem no formato “Chapecoense 14% – Empate 29% – Corinthians 57%”, por exemplo.
Com os templates do Flask eu criei um pequeno site que executa e exibe o resultado desses crawlers. Ficou assim:
Essa foi minha primeira experiência com BeautifulSoup4 e crawlers. Qualquer dúvida ou sugestão, deixe um comentário abaixo. E para ver o código fonte desse pequeno app acesse meu Github.
Nessa semana o projeto em que trabalho precisou de uma forma para exibir emails de usuários durante o processo de cadastro, apenas para relembrar qual endereço o mesmo havia cadastrado na sua conta.
Exibir o email completo seria uma falha de privacidade/segurança muito grande, pois o cadastro é um processo público. Para evitar isso, a equipe decidiu mostrar apenas uma parte do endereço, para que o usuário identificasse caso seja o dono da conta, mas caso não seja não teria como saber qual é o endereço completo.
Para atingir isso, criei dois pequenos métodos: um que substitui partes de uma string por asteriscos e outro que divide o email em username e domínio, para então executar o método anterior em cada parte. O resultado é que o email testedeemail@teste.com se transforma em te********il@tes**.com.
Para deixar o método de substituição da string mais flexível, eu adicionei dois parâmetros (begin_letter_amount, end_letter_amount) que controlam quantas letras serão exibidas no começo e no final da string.
Precisei criar um script que encontra as coordenadas de acordo com um dado endereço. Eles vieram de um arquivo Excel com diversos locais registrados.
Para atingir esse objetivo me baseei em um projeto antigo do meu colega Fernando Freitas Alves. Ele já vinha pronto para ler planilhas Excel e buscar coordenadas para cada endereço, o que facilitou muito meu trabalho.
Precisei alterar diversos comportamentos do script e também atualizei a maneira como ele fazia requests, dado que na época em que ele criou o script não se utilizava o requests do python, ele utilizava urllib e simplejson para parsear os resultados dos requests.
Mandei um pull request apenas com a parte de atualização de urllib + simplejson para o requests no projeto dele. 😉
Abaixo segue um Gist com o código parecido com o que tenho utilizado, comentado em cada parte, para melhor compreensão. Utilizando Python 2.7:
Meu script trabalha para tentar encontrar as coordenadas de milhares endereços. Como a API do Google Maps tem um limite diário, estou utilizando mais de uma API Key.
Com esses dados eu faço um request no minha API e adiciono no banco de dados. Mas você pode fazer o que quiser com eles agora. =)
Atualmente tenho trabalhado com Django em um projeto de API que aproveita a geolocalização do usuário para ordenar os dados e mostrar os resultados mais próximos.
Para fazer isso é preciso utilizar um conjunto de ferramentas específicas para geolocalização que o Django possui, que são conhecidos como GeoDjango.
Nesse texto não irei cobrir as instalações e configurações específicas do banco de dados. Mas elas podem ser vistas aqui.
Começamos adicionando django.contrib.gis no nosso arquivo settings.py e partimos para os nossos models.
Ao invés de importar os models comuns do Django, importamos os models do django.contrib.gis.db. Nesse caso eu criei um abstract model que vai ser utilizado em todos os outros que necessitarem de endereço e localização.
O campo location vem com um tipo especial, o PointField, que irá guardar os dados de geolocalização do endereço.
No model que extende nosso AddressBaseModel utilizamos o GeoManager para substituir o manager dos models comuns do Django.
Agora podemos ordenar o resultado pela distância de um ponto específico.
Na view vamos utilizar o método distance do queryset para “criar” um campo com o mesmo nome e utilizar o order para ordenar por esse novo campo distance.
Para o método distance, precisamos passar uma origem. Origem será o local que o usuário está nesse caso. Para transformar as strings com a latitude e longitude em um ponto de geolocalização, utilizamos a classe Point do django.contrib.gis.geos.
Para formatar o resultado eu criei um método get_distance no StuffSerializer. O objetivo dele é mostrar a distância em metros ou quilômetros.
O resultado será algo como o exemplo abaixo.
Este é um exemplo de como podemos utilizar o GeoDjango para calcular a distância e ordenar os resultados através dela, mas existem diversas outras formas de fazer isso também.