O sonho de todo mundo que tem um projeto de aplicativo é vê-lo viralizar e lotar de gente usando, não é? Pois o meu aplicativo viralizou… e não deu conta da quantidade de acessos.
Isso aconteceu com a Fliptru, meu projeto de plataforma de autopublicação de quadrinhos online.
Resolvi escrever esse post para compartilhar um pouco da experiência de ver a Fliptru explodindo de usuários e saindo do ar graças a um vídeo do Youtube.
Também vou aproveitar pra falar de como resolvi o problema de performance que já vinha afetando a plataforma há anos.
Contexto inicial
Quero começar dando um contexto sobre a história e a situação atual da Fliptru.
Sou a única pessoa que mantém esse projeto rodando, financeira e tecnicamente falando. Desenvolvi a plataforma e a mantenho no ar no meu tempo livre.
Sua primeira versão foi implementada em algumas semanas no primeiro semestre de 2019 e a coloquei no ar usando um serviço de hospedagem de $10 onde o banco de dados e o servidor já estavam inclusos.
Manter a plataforma era muito barato e simples neste começo. Pouca gente usando, poucas funcionalidades, baixo custo do serviço de hospedagem…
Então, ainda em 2019, recebi um aviso de que o serviço bom e barato que eu usava ia simplesmente deixar de existir. Me vi na posição de encontrar uma alternativa pra hospedar a Fliptru em poucos meses.
Contratei um amigo que trabalha com infraestrutura para fazer a migração da aplicação para a AWS.
Ele me deu algumas opções incríveis para a infra do projeto.
Opções com auto-escaling, load balancer e etc (guarde essa informação), mas eu não tinha grana o bastante pra pensar em algo tão avançado e TÃO caro.
Então, entre as opções de infraestrutura que ele me apresentou, escolhi a versão mais barata e menos robusta. Só uma máquina EC2 com Docker rodando e o banco de dados eu mesmo resolveria com um serviço de fora da AWS.
No primeiro ano usei um cupom de 100% OFF na AWS, então, nada de custos muito altos.
Nota: a infra do projeto tem mais detalhes e outros serviços que uso, mas não são relevantes para a história que vou contar, então vou deixá-los de lado.
Bem, depois que o cupom de um ano de AWS na faixa terminou, os custos para manter a plataforma no ar subiram de forma expressiva. O que já era previsto.
Enquanto isso o projeto ganhou relevância entre o nicho de quadrinistas independentes e hoje é referência na área graças a comunidade incrível que se formou em volta da Fliptru, o que me deixa super orgulhoso.
O crescimento orgânico
A nossa comunidade é super engajada e ajuda muito a Fliptru a se divulgar e, consequentemente, a crescer.
Nunca gastei um centavo com anúncios pagos nestes mais de quatro anos de projeto. Mesmo assim, crescemos em uma taxa média de mais de 100% ao ano.
Veja o crescimento usual em 28 dias entre um mês (junho/23) e outro (julho/23) no Google Analytics.


São cerca de 14% a mais de usuários de um mês para o outro.
Lembrando que o GA considera usuário como uma pessoa única que visitou a página no período.
Eu gosto muito de acompanhar esse crescimento pelo Google Analytics e ver quantas pessoas estão usando a Fliptru nestes períodos.
Até agosto de 2023 nós, lentamente, ultrapassamos as 20 mil pessoas lendo quadrinhos independentes na Fliptru. Ver isso acontecendo é incrível!
A lentidão da plataforma
Com o crescimento da comunidade, a partir do segundo pro terceiro ano de operação, as primeiras reclamações de lentidão da plataforma começaram a aparecer.
Em horários de pico a experiência de navegação ficava bem mais lenta do que o normal.
Sempre assumi que o problema era que o serviço de banco de dados que eu usava era péssimo.
Eu recebia alguns erros de timeout do banco de dados durante estes períodos… então parecia obvio que eles tinham um serviço instável (guarde mais essa informação).
Cheguei a testar o Datadog para tentar encontrar o gargalo, mas sem sucesso.
Então continuei assumindo que tinha que migrar o banco de dados para resolver esse problema.
Alguns meses atrás eu implementei o Memcached para usar cache pra mitigar esse problema, já que ele estava ficando cada vez pior.
Depois de aprender muito sobre performance e cache, eu pensei ter conseguido um resultado melhor na Fliptru.
Só que algumas requisições ainda demoravam muito durante horários de pico… parecia que eu ia ter que migrar mesmo o banco de dados, mas não tinha tempo e nem dinheiro pra isso por enquanto.
Até que…
O dia em que a Fliptru parou
Domingo, 20 de agosto de 2023.
Os primeiros alertas do Cronitor (serviço que uso para monitorar a Fliptru) começam a pipocar no meu email.
A plataforma está super lenta e saindo do ar o tempo todo.
Fiquei super frustrado mais uma vez com o serviço de banco de dados e ainda mais decidido que estava na hora de migrar para outro provedor, mas não dava pra ser agora.
Soltei um aviso pra comunidade de que, por “problemas em um serviço terceiro”, estávamos com instabilidade na plataforma durante aquele dia.
Eu esperava que seria mais um dos (raros) dias em que o serviço estava fora do ar.
Abri chamados no suporte do serviço de banco de dados e eles responderam que não havia nada de errado da parte deles.
Fiquei com ainda mais raiva deles e fui pesquisar quanto custava servir o banco na AWS e, imediatamente, desisti da ideia porque era financeiramente inviável.
Tinha que ser o serviço do banco de dados, porque eu estava recebendo centenas de erros de timeout deles.
“Amanhã vou tentar umas mudanças de emergência para diminuir a carga no banco.” – pensei ao ir pra cama naquela noite.
O dia depois de ontem
Acordei cheio de ideias para melhorar a performance da aplicação e, pela manhã, fiquei sambando entre executar as tarefas do meu trabalho “9to5” e lidar com a plataforma caindo o tempo todo.
Até que, do nada, resolvi conferir o Google Analytics… e foi isso que eu vi.

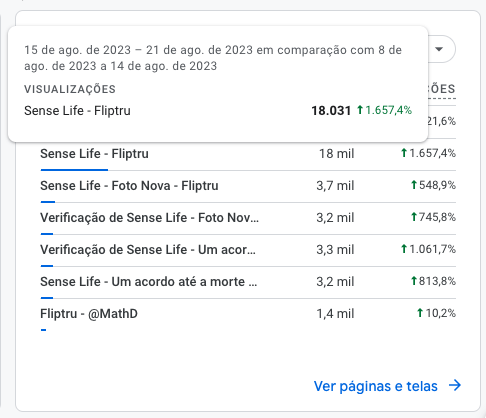
Na verdade o que eu vi foi um número inacreditável no bloco “Usuários nos últimos 30 minutos“, eram cerca de 560 pessoas onde normalmente mostrava 50 e poucas.
Fui checar os detalhes de uso e vi que todo mundo estava lendo o quadrinho Sense Life.
Imediamente segui o meu “protocolo de viralização de quadrinho da Fliptru”.
- Acessar o Google
- Procurar pelo nome do quadrinho que tá viralizando
- Encontrar de onde vem o tráfego pra ele
Normalmente acho um post do Twitter apontando pra algum quadrinho que viralizou por lá.
Note que, por eu ter um protocolo de viralização, isso já aconteceu algumas vezes no passado, mas nunca com o tamanho que Sense Life estava tendo naquele momento.
Seguindo meu “protocolo” eu descobri que o canal AniRap tinha lançado um vídeo-clipe em animação com um rap do quadrinho Sense Life.

Nunca tinha ouvido falar desse canal antes, mas ele tem milhões de visualizações em cada vídeo que lança.
E lá estava, na descrição do vídeo o link oficial pro quadrinho Sense Life é o da Fliptru.
Mesmo com nosso link direto lá, provando que as pessoas não leem descrição de vídeo no Youtube, a maioria das pessoas estava achando Sense Life através da busca no Google.


Olha, Sense Life já é um quadrinho com muito mais engajamento na Fliptru do que a média da plataforma, mas depois desse vídeo a coisa virou uma loucura!
Agora eu tinha que dar um jeito de fazer a plataforma aguentar esse tráfego louco!
Tentando, sem sucesso, manter a Fliptru no ar
Adicionar o cache e remover algumas requisições extras até que ajudou a manter a plataforma no ar por mais tempo. Mas não foi o bastante para os horários de pico.
No d+1 (um dia depois do incidente) a Fliptru continuava caindo e sendo péssima de navegar.
Comecei a ficar desesperado… eram milhares de novas pessoas conhecendo meu projeto e essa não era a experiência que eu queria que eles tivessem no primeiro acesso.
Continuei subindo melhorias e alterações de emergência e soltando avisos pra comunidade do que tava acontecendo.
Mas nada realmente concertava o problema.
No d+4, terça-feira, dia 23, eu decidi abandonar o barco.
“É só isso. Não tem mais jeito. Acabou, boa sorte.”
Vanessa da Mata
“Uma hora o hype vai embora e a plataforma vai voltar ao normal.” – pensei.
Nada como deixar o inconsciente resolver o problema
Não me recordo para onde eu estava dirigindo, mas me lembro de qual era o trecho da estrada onde eu estava na hora em que a solução me veio, no meio de uma conversa com a minha esposa.
Depois de tentar “não pensar mais no problema”, lá estava ela… a causa disso tudo surgiu na minha cabeça como se fosse óbvia!
Não só a causa deste problema atual, mas de todo o problema histórico de lentidão da plataforma.
Durante as inúmeras horas procurando formas de otimizar todas as pontas do aplicativo, estudei as configurações do próprio banco de dados para saber se tinha como otimizar algo por lá.
Lá eu vi que 100 conexões era o máximo que o banco aguentava por vez.
E foi aí que eu percebi o que realmente estava causando tudo isso.
Desde os primeiros meses da Fliptru eu quis que os usuários tivessem informações sobre como os leitores estavam consumindo suas obras.
Pra isso eu criei endpoints que coletam dados de uso toda vez que um usuário lê uma página ou acessa detalhes de um quadrinho.
Bom, dezenas de milhares de pessoas estavam lendo Sense Life.
Ficou super claro que o banco era o gargalo sim, mas não por culpa do serviço terceiro que eu usava, mas sim por conta de um decisão de arqutiteura que eu fiz lá no começo da plataforma e nunca mais tive tempo de repensar.
Parecia tão óbvio agora… a falta que faz ter mais de uma cabeça pensando nas soluções, né?
Bom, saber a causa do problema é 50% da solução.
Agora é sentar na frente do computador e achar um jeito de coletar essas informações de uso sem abrir centenas de conexões com o banco de dados ao mesmo tempo.
Custo x benefício
Como eu comentei antes, a pessoa que fez a migração da infraestrutura da Fliptru tinha me oferecido uma arquitetura que seria auto-escalável e não enfrentaria esses problemas.
Eu devia ter escolhido essa solução mais robusta então?
Não. Nem pensar.
Se eu tivesse escolhido ser auto-escalável, a plataforma até não teria caído durante o viralização de Sense Life, mas eu provavelmente teria uma dívida gigantesca no meu cartão de crédito agora mesmo.
Estou falando de milhares de dólares…
Então, vou deixar a plataforma caindo sempre pra não ter que vender um rim?
Também não. Vou resolver de forma barata.
Resolvendo o problema com baixo-custo
Comecei a quebrar o problema em partes e pensar na solução para uma parte por vez.
Primeiro, vou usar uma operação “bulk” para gravar multiplos dados abrindo só uma conexão por vez.
Assim, milhares de usuários acessando ao mesmo tempo vão abrir uma única conexão com o banco de dados para persistir os dados de uso.
Mas como fazer isso?
Preciso acumular os dados em algum lugar temporátio para depois processá-los.
E se eu usasse o Memcached pra isso?
Estou usando esse serviço para “cachear” as coisas que são lidas, mas e se eu usasse ele para gravar dados temporários também?
Bora tentar, afinal, já estou pagando pelo serviço mesmo. E se não der certo, penso em outra solução.
Na prática eu fiz assim…
Memcached é um banco tipo chave-valor, então gravo uma chave de identificação específica com uma lista de dados relacionados ao uso dos leitores.
'read_data_0': [
{
'user_pk': 10234,
'content_object_pk': 4321,
...
}
]De tempos em tempos um script agendado persiste estes dados no banco de dados relacional usando uma operação bulk.
Claro que isso gera concorrência, já que enquanto um bloco de dados esta sendo processado ele tem que ficar bloqueado para novos dados.
Para lidar com isso, enquanto um bloco está sendo processado ele tem um “status” que não permite que mais dados sejam registrados nele e o endpoint que grava os dados de uso se vira para abrir um novo bloco ou encontrar um que ainda não começou a ser processado para acomodar os dados temporários.
'read_data_0': 'processing'
'read_data_1: [
{
'user_pk': 7263,
'content_object_pk': 7273,
...
}
]Deu muito certo.
Uma solução ultra-simples e que não adicionou NENHUM custo novo para a operação da plataforma.
E sabe o que mais?
Mesmo com o declínio do hype de Sense Life, continuamos com 400% mais usuários acessando nossa plataforma todo dia do que tínhamos no horário de pico antes.
Ainda assim, a Fliptru tá voando. Sem lentidão.
Otimização de baixo-custo feita com sucesso!
Conclusão
Bom, esse é o resultado final do caso da viraliação de Sense Life na Fliptru no Google Analytics.


Uau, cem mil pessoas usando minha aplicação… nunca imaginei isso acontecendo.
Agora que achei uma solução para otimizar a platsaforma, estou super feliz com tudo isso que aconteceu.
Aprendi muita coisa sobre caching e performance.
O estresse valeu a experiência e o resultado final.
Agora, bola pra frente e bora continuar levando a Fliptru além dos seus limites.
Obrigado por ler até aqui e até a próxima!