
O pessoal no escritório está se divertindo muito com o Cartola FC. Graças a Liga que criamos por lá, todos estamos envolvidos em escalar nossos times e para isso eu gosto de ver as probabilidades de resultado dos jogos. Descobri a pouco que o Bing faz uma previsão quando você busca por dois times que irão se enfrentar. Então resolvi automatizar essa busca para me divertir e experimentar o BeautifulSoup4 (BS) para fazer crawler.
A ideia de um crawler é pegar um HTML de um site e procurar informações dentro dele. O BeautfulSoup4 é quem faz o parse deste HTML e nos permite executar métodos que fazem essa busca por informações no mesmo.
Comecei fazendo um app de um arquivo só com o Flask apenas para executar os crawlers facilmente e exibir as informações e dentro dele criei dois métodos que executam crawlers. O primeiro atualiza a tabela de jogos com os resultados (e na primeira execução popula o banco com os jogos) e o segundo executa a busca no Bing e me retorna a previsão de resultado de cada jogo.
Então o primeiro passo é buscar esse HTML no site onde você tem a informação. No caso das informações dos jogos eu fui buscar no site tabeladobrasileirao.net.
Começo utilizando o requests do Python para retornar o HTML dos jogos e seus resultados (no caso dos que já aconteceram).
import requests
r = requests.get('http://www.tabeladobrasileirao.net/')
Depois é a vez do BeautifulSoup4 entrar em ação. Passo o resultado para o BS (com o encode) e ele “parseia” o HTML.
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text.encode('utf-8'), 'html.parser')
E aí começo a procurar. Depois de analisar o HTML do site, descubro onde as informações estão e uso o método find do BS para pegar as informações.
table = soup.find('table', id="jogos")
for row in table.findAll("tr")[1:]:
cells = row.findAll("td")
if len(cells) == 12:
game = {}
game['round'] = int(cells[0].find(text=True))
date_string = cells[1].find(text=True)
date_string = '{}/{}'.format(date_string, '2016')
game['date'] = datetime.datetime.strptime(date_string, "%d/%m/%Y").date()
game['home_team'] = cells[4].find(text=True)
home_team_result = cells[5].find(text=True)
if home_team_result:
game['home_team_result'] = int(cells[5].find(text=True))
else:
game['home_team_result'] = None
away_team_result = cells[7].find(text=True)
if away_team_result:
game['away_team_result'] = int(cells[7].find(text=True))
else:
game['away_team_result'] = None
game['away_team'] = cells[8].find(text=True)
Neste código estou buscando a tabela com id igual a “jogos” e iterando sobre suas células, a partir das linhas da tabela. Como já identifiquei onde estão os dados, comecei a guardá-los em um dicionário (tratando datas, tipos e resultados nulos) que usarei para salvar no banco de dados posteriormente. Por exemplo, cada jogo está em uma linha e a data dele está na segunda coluna, então uso cells[1].find(text=true) para pegar somente o texto da célula.
Omiti a parte de salvar no banco de dados, mas o código todo está disponível no meu Github.
Com todos os jogos salvos é a vez de procurar pela previsão de resultados no Bing.
Mais uma vez começo com o requests e dou um parse no resultado com o BS. Leve em consideração que a variável “game” no código abaixo retorna a string com o jogo em questão, por exemplo, “Internacional x Grêmio” ou “Corinthians x Flamengo”.
r = requests.get(u'http://www.bing.com/search?q={}'.format(game))
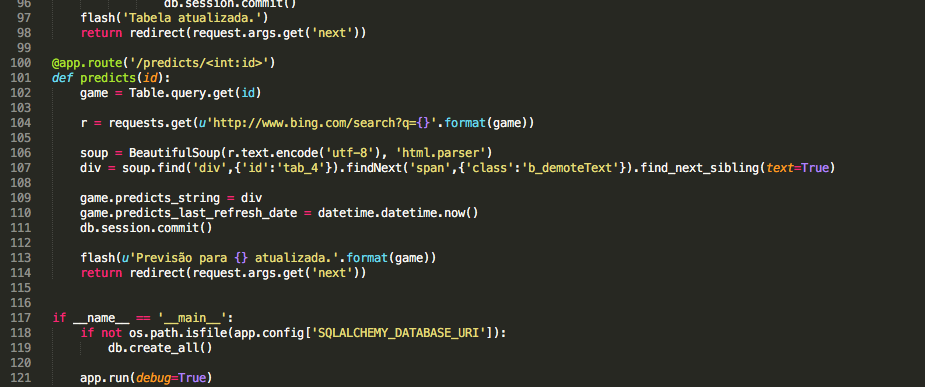
soup = BeautifulSoup(r.text.encode('utf-8'), 'html.parser')
div = soup.find('div',{'id':'tab_4'}).findNext('span',{'class':'b_demoteText'}).find_next_sibling(text=True)
predicts_string = div
Nesse caso foi muito mais difícil achar o local exato no código fonte do resultado da busca do Bing do que foi no caso do tabeladobrasileirao.net. Mas com um pouco de pesquisa e muita tentativa e erro eu acabei chegando no texto de previsão do Bing usando soup.find(‘div’,{‘id’:’tab_4′}).findNext(‘span’,{‘class’:’b_demoteText’}).find_next_sibling(text=True), mais uma vez com text=true para retornar somente o texto do objeto que vem no formato “Chapecoense 14% – Empate 29% – Corinthians 57%”, por exemplo.
Com os templates do Flask eu criei um pequeno site que executa e exibe o resultado desses crawlers. Ficou assim:


Essa foi minha primeira experiência com BeautifulSoup4 e crawlers. Qualquer dúvida ou sugestão, deixe um comentário abaixo. E para ver o código fonte desse pequeno app acesse meu Github.
