Em uma das reuniões dessa última semana na empresa onde trabalho surgiu uma necessidade simples de comunicação: Precisamos que toda a equipe saiba quando um novo release de algum dos nossos repositórios for criado no Github.
Como usamos o Slack como ferramenta de comunicação interna, na hora já pensei:
“Esta é a minha chance de criar um bot para o Slack!”
Sempre tive vontade de fazer algo para o Slack, mas não tinha conseguido achar um tempo e nem um motivo específico para isso. Eu já imaginava que para esse objetivo, avisar sobre um novo release, não seria algo complicado.
Realmente não foi. Em apenas algumas linhas deu pra criar um bot que conecta os webhooks do Github e do Slack utilizando o Flask como meio-campo.
Abaixo o código final da primeira versão.
# coding: utf-8
import os
import requests
from flask import Flask
from flask import request
app = Flask(__name__)
slack_webhook_url = os.getenv('SLACK_WEBHOOK_URL')
@app.route("/", methods=['POST', ])
def webhook():
action = request.json['action']
release = request.json['release']
repository = request.json['repository']
slack_data = {
"text": "A new release from *{repo_name}* was {action}!\n"
"Click <{release_url}|Release {tag_name}> for more details".format(action=action,
repo_name=repository['name'],
release_url=release['url'],
tag_name=release['tag_name'])
}
response = requests.post(slack_webhook_url, json=slack_data)
if response.status_code != 200:
raise ValueError(
'Request to slack returned an error {}, the response is:\n{}'.format(response.status_code,
response.text)
)
return ""
Pelo pouco tempo que passei lendo sobre como fazer um bot para o Slack eu entendi que você cadastra um Incoming Webhook e eles geram uma URL a qual você irá executar um request do tipo POST enviando a mensagem que você quer que um canal específico receba.
É realmente muito simples, porque a própria URL já carrega os tokens que são gerados para você.
Existem diversas outras funcionalidades que podem ser criadas em um bot para o Slack e a documentação deles cobre tudo. Mas vou falar apenas desse pequeno release-alert que criei.
Explicando linha por linha
Antes de começar a escrever o código vou precisar do Flask e de alguns outros pacotes. Então começo ainda na linha de comando do shell.
$ pip install Flask
$ pip install requests
Depois eu coloco a URL que gerei no Incoming Webhooks do Slack em uma variável de ambiente que chamo de SLACK_WEBHOOK_URL. Depois basta importá-la para dentro do código.
$ export SLACK_WEBHOOK_URL=<aqui vai a url do webhook do slack>
Agora crio meu arquivo Python chamado bot.py. Como estou usando o Flask, só vou precisar desse arquivo e praticamente nada mais.
Nas primeiras linhas começo importando o que vou utilizar e criando o app do Flask.
import os
import requests
from flask import Flask
from flask import request
app = Flask(__name__)
Trago para dentro do código a variável de ambiente que criei antes.
Agora vou começar a montar o meu endpoint. Ele receberá um evento POST enviado pelo webhook do Github. Para que isso aconteça você precisa cadastrar uma URL de webhook no settings do seu projeto no Github.
No meu caso, eu cadastrei a webhook no settings da organização, já que queria que todos os projetos da empresa disparassem o aviso. Mas funciona do mesmo jeito em qualquer um dos casos.
Quando cadastrei o meu webhook no Github especifiquei que gostaria de receber apenas os eventos relacionados ao release dos projetos.
Para testar o código localmente eu utilizei o ngrok. Explico como usar o ngrok em outra publicação.
O Flask facilita recuperar informações de um corpo de um request JSON com o seu objeto request nativo. Basta chamar request.json e ele retorna um dicionário.
Agora eu vou montar o corpo da mensagem que enviarei para o Slack. O formato pedido é muito simples: um JSON com um campo ‘text’.
slack_data = {
"text": "A new release from *{repo_name}* was {action}!\n"
"Click <{release_url}|Release {tag_name}> for more details".format(action=action,
repo_name=repository['name'],
release_url=release['url'],
tag_name=release['tag_name'])
}
Esse dicionário será transformado em um JSON pela próxima linha. O pacote requests já resolve isso para mim através do argumento json.
response = requests.post(slack_webhook_url, json=slack_data)
if response.status_code != 200:
raise ValueError(
'Request to slack returned an error {}, the response is:\n{}'.format(response.status_code,
response.text)
)
return ""
No final do arquivo estou apenas tratando algum possível erro. Caso o requests retorne um status_code diferente de 200 eu levanto uma exceção.
No final retorno uma string vazia, porque cada endpoint do Flask precisa retornar alguma coisa para não levantar erros.
Para que meu bot fique disponível o tempo todo, fiz um deploy na minha conta gratuita do Heroku. E voilá!
Este é um tutorial no estilo passo-a-passo para a criação de um chatbot simples para o Facebook Messenger. Ele foi escrito como conteúdo para uma pequena apresentação que farei em um evento interno de compartilhamento de conhecimento da TIKAL TECH, empresa em que trabalho.
Existem diversas maneiras de se criar um bot para o Messenger, mas neste tutorial eu utilizarei apenas o microframework para web escrito em Python chamado Flask e nada mais.
Esse tutorial resume algumas das coisas que aprendi durante o desenvolvimento de um outro projeto.
Passo 1
Criando um aplicativo e vinculando com uma fanpage
Acesse o dashboard do Facebook Developers e crie um aplicativo. No tipo de aplicativo escolha “Aplicativos para o Facebook Messenger”. Se você não tiver uma página para vincular o aplicativo, crie uma também.
Com a página criada, entre novamente no dashboard e gere um token para o aplicativo ser vinculado à página.
Passo 2
Começando a programar o backend
Vamos utilizar o microframework Flask para facilitar esse desenvolvimento, mas qualquer outro framework web pode ser utilizado.
Se você está acostumado a trabalhar com Python você pode pular alguns dos passos abaixo.
Vamos começar criando um ambiente virtual na linha de comando e instalando o Flask, o requests e o gunicorn. Precisaremos dos dois primeiros para nosso chatbot e o último será para o deploy.
Escolha o diretório que você vai utilizar e digite os seguintes comandos.
Agora temos um arquivo index.py no nosso diretório chatbot. É nele que faremos os próximos passos do nosso tutorial.
Começamos com o básico do Flask.
import os
from flask import Flask, request
token = os.environ.get('FB_ACCESS_TOKEN')
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def webhook():
return 'Nothing'
if __name__ == '__main__':
app.run(debug=True)
Esse arquivo tem o básico do que precisamos para rodar um app no Flask.
O token que estamos pegando de uma variável de ambiente é o token que geramos no dashboard do Facebook.
Para adicioná-lo como variável de ambiente execute na linha de comando:
$ export FB_ACCESS_TOKEN=<cole o token gerado>
Passo 3
Configurando os Webhooks
Temos que configurar um webhook para que o Facebook saiba para onde enviar as requisições do chat.
Para isso utilizaremos o ngrok para “tunelar” nosso localhost. Para saber como funciona, veja esta publicação.
Vamos rodar nosso servidor local com o Flask. Na linha de comando com o virtualenv ativado, digite:
(chatbot)$ python index.py
Abra outra janela de terminal para iniciar o ngrok.
./ngrok http 5000
Agora temos um endereço web com HTTPS para cadastrar no dashboard do Facebook. Basta ir até o painel Webhooks e clicar em Configurar Webhooks.
Antes de cadastrar o endereço, é preciso adicionar uma parte a mais no nosso index.py. O bloco em negrito tem o que é preciso para que o Facebook aceite esse link como elegível para webhook.
def webhook():
if request.method == 'POST':
pass
elif request.method == 'GET': # Para a verificação inicial
if request.args.get('hub.verify_token') == os.environ.get('FB_VERIFY_TOKEN'):
return request.args.get('hub.challenge')
return "Wrong Verify Token"
return "Nothing"
Coloque o endereço gerado pelo ngrok, por exemplo https://7f3o6bd7.ngrok.io, e crie uma frase de segurança. Essa frase colocamos na variável de ambiente FB_VERIFY_TOKEN que você pode ver no código acima.
(chatbot)$ export FB_VERIFY_TOKEN=<digite qualquer frase aqui>
Com isso já somos capazes de registrar nosso endereço do chatbot no Facebook.
Para finalizar, no mesmo painel de webhooks você deve “inscrever” sua página criada ao webhook adicionado. Essa parte é bem autoexplicativa.
Passo 4
Lendo a mensagem e respondendo
Agora vamos adicionar uma maneira de lermos o que o usuário nos enviou pelo Messenger. Isso é feito verificando os dados enviados na requisição que o chat nos envia via POST.
Então vamos adicionar ao nosso código o seguinte trecho:
import os
import requests
import traceback
import json
(...)
def webhook():
if request.method == 'POST':
try:
data = json.loads(request.data.decode())
text = data['entry'][0]['messaging'][0]['message']['text']
sender = data['entry'][0]['messaging'][0]['sender']['id']
payload = {'recipient': {'id': sender}, 'message': {'text': "Hello World"}}
r = requests.post('https://graph.facebook.com/v2.6/me/messages/?access_token=' + token, json=payload)
except Exception as e:
print(traceback.format_exc())
elif request.method == 'GET': # Para a verificação inicial
(...)
Explicando o que estamos fazendo. Adicionamos os imports necessários no topo do arquivo index.py e dentro do nosso método webhook verificamos se a requisição chegou como POST.
Com o data = json.loads(request.data.decode()) nós capturamos o corpo da mensagem que nos foi enviado pelo Messenger.
Com o trecho text = data['entry'][0]['messaging'][0]['message']['text']conseguimos pegar o texto que o usuário enviou via chat.
Pra saber quem enviou, usamos o trecho sender = data['entry'][0]['messaging'][0]['sender']['id']. Essa informação é necessária para que possamos enviar uma resposta para o usuário correto.
No trecho payload = {'recipient': {'id': sender}, 'message': {'text: "Hello World"}} nós montamos o corpo da nossa resposta ao usuário.
Para finalizar, respondemos enviando uma requisição para o endereço da API do Facebook Messenger com o corpo criado anteriormente. O trecho referente ao envio segue abaixo.
r = requests.post('https://graph.facebook.com/v2.6/me/messages/?access_token=' + token, json=payload)
Colocamos tudo isso dentro de um try/except para capturar um possível erro que imprimiremos no console. Isso fazemos com o trecho final do código que acabamos de adicionar.
except Exception as e:
print(traceback.format_exc())
Com isso, respondemos um Hello World para cada entrada que o usuário nos enviar.
Passo 5
Tornando o chatbot em algo útil
Como responder Hello World para cada mensagem é algo totalmente inútil para um bot fazer, vamos colocar uma funcionalidade aproveitando a documentação do Messenger, que é bem completa.
Vamos pegar a localização do usuário e enviar informações sobre o clima atual em sua localidade.
Primeiro criamos uma função que monta um payload com formatoQuick Reply do Messenger. O formato que precisamos enviar para ter esse resultado é facilmente encontrado na documentação do Messenger. Nela definiremos que queremos um tipo location.
Agora, quando formos enviar uma mensagem para nosso usuário, utilizamos essa função no lugar do antigo payload.
payload = location_quick_reply(sender)
Isso vai enviar uma opção para o usuário nos enviar sua localização. Como mostra a imagem abaixo.
Vamos receber essa localização de maneira diferente do que um texto comum, ela virá como um anexo. Dessa forma mudamos nossa verificação de texto para o bloco abaixo.
if request.method == 'POST':
try:
data = json.loads(request.data.decode())
print(data)
message = data['entry'][0]['messaging'][0]['message']
sender = data['entry'][0]['messaging'][0]['sender']['id'] # Sender ID
if 'attachments' in message:
if 'payload' in message['attachments'][0]:
if 'coordinates' in message['attachments'][0]['payload']:
location = message['attachments'][0]['payload']['coordinates']
latitude = location['lat']
longitude = location['long']
else:
text = message['text']
payload = location_quick_reply(sender)
r = requests.post('https://graph.facebook.com/v2.6/me/messages/?access_token=' + token,
json=payload)
Nesse bloco verificamos se o corpo da requisição que o Messenger nos enviou possui uma chave attachments e se possui uma chave payload com as coordenadas da localização.
Se não vier nesse formato é porque ele enviou uma mensagem normal de texto, então reenviamos o botão que pede sua localização.
Agora que pegamos a latitude e longitude, podemos utilizar uma API aberta de clima para enviar as informações para nosso usuário.
Eu escolhi a OpenWeatherMap para isso. Basta se inscrever e gerar uma chave de API no site deles e você já pode começar a fazer requisições variadas para receber informações de clima do mundo inteiro.
Adicionei a chave de API deles numa variável de ambiente para utilizar nas requisições que farei dentro do código e pronto.
(chatbot)$ export WEATHER_API_KEY=<digite a api key>
Agora podemos acessar o endpoint que eles fornecem para current weathere pegar a temperatura e outros dados climáticos do local do usuário.
Logo após o trecho do código onde pegamos a latitude e longitude, adicionamos uma requisição para a API do OpenWeatherMap para montar a resposta que daremos ao nosso usuário.
Basicamente analisei a resposta da API do OpenWeatherMap e peguei as informações que gostaria de exibir ao usuário. Depois disso montei um bloco de texto simples exibindo algumas das informações.
Pronto! Agora temos uma funcionalidade para nosso bot experimental.
Passo 6
Fazendo o deploy
Vamos colocar nosso novo bot em um servidor para que ele fique disponível constantemente. Como eu falei anteriormente é preciso uma conexão segura (HTTPS) para que o Facebook aceite a URL do chatbot.
Com o Heroku é muito simples fazer o deploy. Basta que o seu código esteja no github, por exemplo, e com um clique ele fica online.
Para fazê-lo funcionar no Heroku é preciso adicionar dois novos arquivos ao nosso projeto. O Procfile e o runtime.txt. O primeiro configura o servidor web e o segundo define que estamos usando o Python 3.
Se você estiver utilizando a versão 2 do Python, o segundo arquivo é desnecessário.
O arquivo Procfile ficará assim:
web: gunicorn index:app
E o runtime.txt assim:
python-3.5.2
Criamos uma conta no Heroku e adicionamos um novo app. Em seguida vamos na aba Deploy e conectamos com o Github. Com isso basta escolher o seu repositório e clicar em Deploy Branch.
Abas do Dashboard do Heroku
Precisamos adicionar nossas variáveis de ambiente. Para isso devemos ir à aba Settings e adicionar manualmente por lá. É simples e autoexplicativo.
Agora testamos nossa URL, que será algo como https://<nome_do_app>.herokuapp.com.
Voltamos ao dashboard de developers do Facebook para mudar nosso webhook configurado. Lembra que fizemos isso com o endereço que o ngrok nos forneceu no passo três? Agora vamos mudar a URL para a nova que o Heroku nos forneceu.
Aprovação do Facebook
Com nosso bot funcional e online, agora temos que deixá-lo em aprovação no dashboard de developers do Facebook.
Basta preencher o que eles pedem por lá e aguardar até cinco dias para que seu bot possa ser usado por qualquer usuário do Facebook.
Conclusão
O Facebook aprovou rapidamente o chatbot que chamei de Climão. Isso porque utilizamos apenas a permissão de messages do Webhook, que é a mais simples.
Para utilizar esse bot acesse a Página do Facebook e envie uma mensagem para o Climão. =)
O código que criamos durante esse tutorial está disponível no Github.
Qualquer dúvida, entre em contato pelas respostas abaixo.
O pessoal no escritório está se divertindo muito com o Cartola FC. Graças a Liga que criamos por lá, todos estamos envolvidos em escalar nossos times e para isso eu gosto de ver as probabilidades de resultado dos jogos. Descobri a pouco que o Bing faz uma previsão quando você busca por dois times que irão se enfrentar. Então resolvi automatizar essa busca para me divertir e experimentar o BeautifulSoup4 (BS) para fazer crawler.
A ideia de um crawler é pegar um HTML de um site e procurar informações dentro dele. O BeautfulSoup4 é quem faz o parse deste HTML e nos permite executar métodos que fazem essa busca por informações no mesmo.
Comecei fazendo um app de um arquivo só com o Flask apenas para executar os crawlers facilmente e exibir as informações e dentro dele criei dois métodos que executam crawlers. O primeiro atualiza a tabela de jogos com os resultados (e na primeira execução popula o banco com os jogos) e o segundo executa a busca no Bing e me retorna a previsão de resultado de cada jogo.
Então o primeiro passo é buscar esse HTML no site onde você tem a informação. No caso das informações dos jogos eu fui buscar no site tabeladobrasileirao.net.
Começo utilizando o requests do Python para retornar o HTML dos jogos e seus resultados (no caso dos que já aconteceram).
import requests
r = requests.get('http://www.tabeladobrasileirao.net/')
Depois é a vez do BeautifulSoup4 entrar em ação. Passo o resultado para o BS (com o encode) e ele “parseia” o HTML.
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text.encode('utf-8'), 'html.parser')
E aí começo a procurar. Depois de analisar o HTML do site, descubro onde as informações estão e uso o método find do BS para pegar as informações.
Neste código estou buscando a tabela com id igual a “jogos” e iterando sobre suas células, a partir das linhas da tabela. Como já identifiquei onde estão os dados, comecei a guardá-los em um dicionário (tratando datas, tipos e resultados nulos) que usarei para salvar no banco de dados posteriormente. Por exemplo, cada jogo está em uma linha e a data dele está na segunda coluna, então uso cells[1].find(text=true) para pegar somente o texto da célula.
Omiti a parte de salvar no banco de dados, mas o código todo está disponível no meu Github.
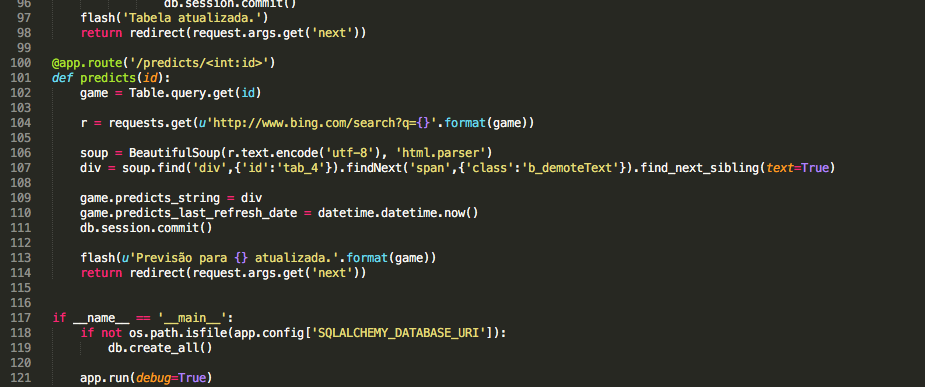
Com todos os jogos salvos é a vez de procurar pela previsão de resultados no Bing.
Mais uma vez começo com o requests e dou um parse no resultado com o BS. Leve em consideração que a variável “game” no código abaixo retorna a string com o jogo em questão, por exemplo, “Internacional x Grêmio” ou “Corinthians x Flamengo”.
r = requests.get(u'http://www.bing.com/search?q={}'.format(game))
soup = BeautifulSoup(r.text.encode('utf-8'), 'html.parser')
div = soup.find('div',{'id':'tab_4'}).findNext('span',{'class':'b_demoteText'}).find_next_sibling(text=True)
predicts_string = div
Nesse caso foi muito mais difícil achar o local exato no código fonte do resultado da busca do Bing do que foi no caso do tabeladobrasileirao.net. Mas com um pouco de pesquisa e muita tentativa e erro eu acabei chegando no texto de previsão do Bing usando soup.find(‘div’,{‘id’:’tab_4′}).findNext(‘span’,{‘class’:’b_demoteText’}).find_next_sibling(text=True), mais uma vez com text=true para retornar somente o texto do objeto que vem no formato “Chapecoense 14% – Empate 29% – Corinthians 57%”, por exemplo.
Com os templates do Flask eu criei um pequeno site que executa e exibe o resultado desses crawlers. Ficou assim:
Essa foi minha primeira experiência com BeautifulSoup4 e crawlers. Qualquer dúvida ou sugestão, deixe um comentário abaixo. E para ver o código fonte desse pequeno app acesse meu Github.
Mandrill é um serviço para disparo de emails transacionais, ele possui relatórios e você pode receber os eventos de cada mensagem (enviado, aberto, click em link, etc) enviada via Webhook.
Procurando uma forma de autenticar o Webhook do Mandrill com Python, o qual eu já havia feito com PHP, eu encontrei esse artigo que mostrava como fazer utilizando o framework Webapp2 e usando uma versão 2.7 do Python. Como eu utilizo Flask com Python 3.4, tive que fazer algumas modificações, mas consegui fazer funcionar.
Segue o trecho de código que estou utilizando:
def calc_mandrill_signature(raw, key):
import hashlib
import hmac
import base64
digest = hmac.new(key.encode('utf-8'), raw.encode('utf-8'), hashlib.sha1).digest()
hashed = base64.encodestring(digest).decode("utf-8").rstrip('\n')
return hashed
def verify_mandrill_signature(request):
'''
Mandrill includes an additional HTTP header with webhook POST requests,
X-Mandrill-Signature, which will contain the signature for the request.
To verify a webhook request, generate a signature using the same key
that Mandrill uses and compare that to the value of the
X-Mandrill-Signature header.
:return: True if verified valid
'''
mandrill_signature = request.headers['X-Mandrill-Signature']
mandrill_key = 'aqui vai a API key do seu webhook'
signed_data = request.url
sorted_key = sorted(request.form)
for k in sorted_key:
signed_data += k
signed_data += request.form[k]
expected_signature = calc_mandrill_signature(signed_data, mandrill_key)
return expected_signature == mandrill_signature
@app.route('/webhook', methods=['POST'])
def event_webhook():
if not verify_mandrill_signature(request):
abort(403)
import json
data = json.loads(request.form['mandrill_events'])
for e in data:
'''
Insira o que você quiser fazer com os resultados dos eventos...
'''
A principal vantagem de se utilizar um microframework para criar um sistema web é a pouca quantidade de “regras” que se precisa seguir no desenvolvimento. O que quero dizer é que se ganha liberdade para escolher o que e como utilizar as facilidades que o framework provém.
Com o advento da liberdade vem a pergunta: qual é o melhor jeito de fazer?
Como de costume, assim que comecei a utilizar o microframework Flask, escrito em Python, segui diversos tutoriais que encontrei na internet para dar os primeiros passos. Fiz alguns sistemas pequenos para aprender e logo vieram as dúvidas. Pesquisando mais e mais percebi que existem diversas maneiras de se estruturar uma aplicação com ele.
E a lição mais interessante que tirei com tudo isso é que deve-se criar seu próprio jeito de fazer as coisas. De acordo com seu background e com seu conhecimento anterior o desenvolvedor vai naturalmente criando seu “estilo” de estruturar seu código e seus sistemas como um todo.
Criando pequenos sistemas não se tem dificuldades com a estrutura, mas a partir do momento que o sistema cresce a coisa muda de figura. Quase todos os tutoriais estilo “hello world” em Flask tem o mesmo formato: um arquivo único que possui todas as chamadas e roda o sistema, como no exemplo abaixo.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
É claro que para criar um sistema mais complexo colocar tudo em um arquivo único é uma péssima ideia. Mas esse tipo de exemplo serve para dar a noção de como o framework é simples.
Mas como estruturar um sistema maior? Nesse caso se cria o arquivo que contém as rotas e suas funções, um arquivo que carrega o aplicativo e um arquivo com o mapeamento do banco de dados. Uma estrutura de diretórios mais ou menos como no exemplo abaixo.
/app
__init__.py
models.py
views.py
/run.py
Até aí tudo bem, ainda se tem uma aplicação bem simples. Adicionamos os diretórios de templates, de arquivos estáticos e o arquivo com as configurações e teremos a estrutura padrão de um sistema simples em Flask.
Ficou um pouquinho mais complexo, mas ainda segue o padrão de tutoriais básicos de utilização do Flask.
Nesse caso, todas as rotas que o sistema terá ficarão em apenas um único arquivo. Pode-se imaginar que isso não é uma boa ideia no caso de sistemas mais complexos, correto?
Basta imaginar a quantidade de linhas que o arquivo views.py pode atingir… a manutenção e o entendimento dele ficarão mais difíceis. Sabe-se que, principalmente para scripts Python, isso não é a melhor opção, pois a ideia é que o código seja simples e legível.
É aí que entram os Blueprints.
Blueprints
Existem diversas formas de utilizar Blueprints no Flask, mas eu basicamente tenho utilizado como aprendi com um vídeo de Miguel Grinberg para a PyCon 2014 (se não me engano): uma forma de separar e modularizar as rotas do aplicativo.
Funciona da seguinte maneira. Em vez de termos um arquivo para todas as rotas do sistema, modularizamos as rotas utilizando arquivos separados e registrando Blueprints para cada um deles.
Em uma tradução livre da documentação do Flask:
Um Blueprint funciona de forma parecida com o objeto de aplicação do Flask, mas não é a mesma coisa. Poderiam ser criadas várias aplicações separadas, mas elas não compartilhariam as mesmas configurações e seriam tratadas na camada WSGI e não na camada do Flask. Já os Blueprints compartilham as mesmas configurações e são uma forma de separar funções dentro da mesma aplicação.
Como eu uso os Blueprints
Para cada módulo que defino no sistema eu crio um arquivo e registro seu Blueprint, como no exemplo abaixo, que simula o arquivo meumodulo.py.
Dessa maneira eu crio todas as rotas desse “módulo” específico. Para registrar o Blueprint é preciso adicionar a linha abaixo no arquivo __init__.py, depois de inicializar o objeto app do Flask.
from .meumodulo import meumodulo
app.register_blueprint(meumodulo)
Se quiser que o novo módulo tenha um prefixo para todas as suas rotas, basta adicionar url_prefixao registro do Blueprint.
Para evitar dependências circulares, podemos criar uma função que registre os Blueprints e a chamamos ao final do arquivo __init__.py, como mostra o exemplo abaixo.
def register_blueprints(app):
from .meumodulo import meumodulo
from .outromodulo import outromodulo
app.register_blueprint(meumodulo, url_prefix='/modulo')
app.register_blueprint(outromodulo, url_prefix='/outromodulo')
register_blueprints(app)
Conclusão
Depois de tudo isso, ainda utilizo uma extensão do Flask chamada Flask-Script para criar um arquivo manager.py no lugar do arquivo run.py. Mas vou explicar melhor sobre isso em uma post futuro.
Essas são apenas algumas dicas que mostram como eu tenho utilizado o microframework Flask para alguns dos meus projetos. Sou relativamente novo com Python e com Flask e por isso tenho certeza de que no futuro terei descoberto novas formas de estruturar os sistemas maiores que farei, mas por enquanto essas são as dicas que tenho para dar para quem se encontra na mesma situação de estudante que eu. Espero poder ter ajudado.
Qualquer dúvida ou sugestão, por favor deixe seu comentário abaixo que responderei sempre que possível.
Depois de concluir um sistema simples (em Python Flask) para guardar informações em um banco de dados, eu o publiquei no meu servidor para disponibilizar para o usuário final (deploy).
Foi a primeira vez que fiz um deploy de um sistema desenvolvido em Flask (que é um micro framework web em Python que tenho estudado e utilizado ultimamente, como comentei neste texto).
Tenho uma conta no Webfaction e foi lá que fiz o deploy do sistema. O processo foi baseado em uma mistura de alguns tutoriais achados na internet e também de tentativa e erro. Entretanto todos eles eram baseados em Python 2.7 e o Webfaction já disponibilizou o WSGI com Python 3.4. Depois de algumas alterações para suprir isso e mais pesquisa eu consegui colocar o sistema para funcionar.
O deploy foi feito para rodar com virtualenv, como mostra essa referência que encontrei neste link. O que tive mesmo que mudar da referência foi a forma de executar o arquivo Python que ativa o ambiente virtual (activate_this.py). No Python 2.7 utilizamos execfile() para rodar o script que ativa o ambiente (como você pode ver no Step 6 do artigo que referenciei acima) e precisei substituir por exec() do Python 3.4.
Só consegui descobrir que o erro era esse acompanhando os logs do servidor a cada vez que fazia uma mudança no código e executava um restart no Apache. No caso do Webfaction os logs ficam em /home/<seuUsuario>/logs/user/error_<seuApp>.log.
Estou gostando muito de trabalhar com o Python e com o Flask. Desenvolver com este framework é muito ágil e dinâmico. O Flask tem diversas extensões que facilitam a vida do desenvolvedor e ainda assim, por não virem no código-fonte do framework, te deixam a escolha de usar ou esta ou aquela extensão. O que é muito bom, pois dependendo do escopo do projeto podemos precisar ou não de determinadas extensões.
Neste projeto, que comento neste texto, estou utilizando as extensões Flask-Login (controle de acesso), Flask-SQLAlchemy (ORM) e Flask-WTF (para formulários). Em textos futuros falarei um pouco mais sobre as extensões do Flask.
Pra quem não sabe, os arquivos AIML (Artificial Intelligence Markup Language) são marcações baseadas em XML para inteligência artificial. Usando a biblioteca PyAIML fica muito simples fazer um chatbot em Python. Mas eu queria fazê-lo via web e foi aí que o Flask entrou.
Utilizei o Flask apenas para lidar com os requests e responses via web. Ou seja, ele recebe uma pergunta vinda do navegador e devolve uma resposta do bot.
Para ver o código-fonte completo do meu chatbot, acesse meu github.
Vendo o código-fonte, percebe-se que na raiz temos apenas o diretório app e o lib, além do arquivo run.py, que roda o servidor. Dentro do diretório app temos os arquivos do Flask: __init__.py e o views.py. No diretório lib está a biblioteca PyAIML e os arquivos AIML, importados da A.L.I.C.E. AI Foundation. Nestes arquivos eu fiz pouquíssimas alterações para o funcionamento básico do Jarvis, nome que dei ao meu chatbot.
Dentro do arquivo app/__init__.py eu importo o Flask e biblioteca PyAIML, para poder utilizá-la no arquivo app/views.py. Perceba que também importo o arquivo brain.brn, que é a “compilação” dos arquivos AIML, ou seja, é o cérebro do bot. Se ele não existir, o Kernel da biblioteca PyAIML vai criá-lo. Exemplo nas linhas abaixo, retiradas do arquivo app/__init__.py.
Uma pequena observação, estou importando os arquivos com os.path.join() para que não precise me preocupar se estou em sistema operacional Windows ou em Unix-based. Isso foi necessário porque no Windows as barras que separam os arquivos são inversas às dos sistemas baseados em Unix (como Linux e MacOS).
No arquivo app/views.py encontramos as definições de rotas (@app.route()) e definimos o que cada endereço web vai fazer no sistema. No caso, temos o / ou /index, que apenas mostra o template básico, através do método render_template do Flask, e temos o /talk, que recebe a “pergunta” do browser e envia a resposta transformada em um objeto JSON com o método jsonify do Flask. Os outros métodos são apenas handlers para os erros 404 (página não encontrada) e 500 (erro interno do servidor). Veja o index e o talk no exemplo abaixo, retirado do arquivo app/views.py.
Lembrando que quando chamamos k.respond() no método talk() estamos chamando a biblioteca PyAIML para fazer o trabalho pesado por nós. Já a importamos no arquivo app/__init__.py e a passamos para a variável app.
É importante lembrar que aquilo que fomos utilizar em um programa Python tem que ser importado. Por isso é comum vermos os comandos import no começo dos arquivos. Por exemplo, no arquivo app/views.py eu importei o render_template, o request e o jsonify do Flask e o app e k (que contem a biblioteca PyAIML) do nosso app iniciado no arquivo app/__init__.py.
from flask import render_template, request, jsonify
from app import app, k
Com a biblioteca PyAIML fazendo a interpretação dos arquivos AIML, o Flask tinha pouquíssimo trabalho pela frente. Com apenas alguns poucos métodos escritos eu consegui rodar o aplicativo web. Isto é algo que tem me agradado muito no Python e no Flask.
Utilizar o PyAIML também foi simples, mas para entender como personalizar o bot (mudar o nome, nascimento, preferências, etc) eu levei um tempinho. Precisava entender que os “predicates” do bot precisavam ser mudados no arquivo lib/pyaiml/aiml/Kernel.py da biblioteca. Para facilitar, criei um arquivo chamado lib/pyaiml/aiml/BotPredicates.py e o importei no Kernel.py, como mostro abaixo.
import BotPredicates
# Set up the bot predicates
self._botPredicates = BotPredicates.bot
Acabou sendo mais simples do que eu imaginava criar o Jarvis. Agora vou continuar brincando um pouco com ele. Quero adicionar reconhecimento de voz para que o usuário possa conversar com o Jarvis. Também quero que o usuário se registre com login e senha, para que o Jarvis já conheça seus amigos quando eles vierem conversar. A medida que eu for desenvolvendo essas novas funcionalidades vou postando algumas notas por aqui.
Sou programador PHP desde 2001 e trabalhei somente com essa linguagem por muito tempo. Em 2012 eu tive uma pequena experiência, graças a um colega de trabalho, com Python através do framework para web Django. Comecei a fazer algumas aplicações simples para aprender. Mas logo após deixar a empresa que trabalhava, acabei parando por ali mesmo.
Este ano resolvi voltar a aprender o Python, gosto muito dessa linguagem e gostaria de ser proficiente nela. Como tudo que aprendo acaba sendo de forma autodidata, fui atrás de alguns tutoriais para voltar a estudar.
Para recomeçar, escolhi um tutorial muito interessante sobre Flask, um microframework para web escrito em Python. O tutorial chama-se The Flaks Mega Tutorial e aborda praticamente tudo que você precisa para fazer uma pequena aplicação web com Flask. Eu recomendo.
O Python e o Flask
Desde o primeiro contato que tive com Python, em 2012, eu achei sua sintaxe incrível. É muito simples e “readable“. Foi uma das primeiras coisas que me chamou atenção nessa tecnologia.
Quando você programa por muito tempo em uma linguagem específica, você acaba ficando viciado em certas coisas específicas dela. É muito gostoso poder experimentar uma forma diferente de programar e a sintaxe do Python deixa tudo mais interessante ainda.
Já o Flask tem me parecido extremamente prático para construir aplicações. Mas ainda estou muito no início para falar mais sobre ele. Só posso dizer que estou gostando bastante das facilidades que ele oferece.
Outra coisa que tem me chamado bastante a atenção com o Python são as empresas que tem migrado de outras linguagens para ele por conta da performance. Assisti diversas palestras e li publicações sobre empresas fazendo essa migração, mas não tenho informações o suficiente sobre isso para falar mais, por enquanto.
Vou continuar meus estudos e o que achar interessante vou publicando por aqui.