Eu construi uma página estática em HTML, CSS e JS para ser uma espécie de portfólio e cartão pessoal para mim e queria colocar uma seção com os artigos deste blog nela. A melhor maneira de acessar esses artigos sem muito esforço é usando o RSS Feed do blog.
Mas a página é “estática”, então eu poderia usar no máximo o Javascript para ler o Feed do blog. Uma opção seria acessá-lo via Ajax e processar os dados em seguida, mas se o Feed for de outra origem (domínio diferente, que não era o meu caso, mas pode ser o seu) ia acabar esbarrando em um erro de segurança (CORSError) e não funcionaria.
Então encontrei uma solução (no link de referência no final do artigo), usar uma API do Google que lê um Feed e retorna um JSON com as informações dele.
Segue abaixo uma versão do código que estou utilizando na página, totalmente comentado.
Os items que temos disponíveis para acesso, como mostra a imagem abaixo, são o autor, categorias e tags, o conteúdo inteiro em HTML, um pequeno snippet do conteúdo em texto puro, a URL do artigo, a data de publicação e o título. Eu senti falta do retorno das mídias, como fotos, por exemplo, mas se for necessário a opção seria pegá-las do próprio HTML que retorna em “content“.
É isso aí, qualquer dúvida ou sugestão deixe nos comentários abaixo. Para ver esse código em funcionamento acesse o site.
O pessoal no escritório está se divertindo muito com o Cartola FC. Graças a Liga que criamos por lá, todos estamos envolvidos em escalar nossos times e para isso eu gosto de ver as probabilidades de resultado dos jogos. Descobri a pouco que o Bing faz uma previsão quando você busca por dois times que irão se enfrentar. Então resolvi automatizar essa busca para me divertir e experimentar o BeautifulSoup4 (BS) para fazer crawler.
A ideia de um crawler é pegar um HTML de um site e procurar informações dentro dele. O BeautfulSoup4 é quem faz o parse deste HTML e nos permite executar métodos que fazem essa busca por informações no mesmo.
Comecei fazendo um app de um arquivo só com o Flask apenas para executar os crawlers facilmente e exibir as informações e dentro dele criei dois métodos que executam crawlers. O primeiro atualiza a tabela de jogos com os resultados (e na primeira execução popula o banco com os jogos) e o segundo executa a busca no Bing e me retorna a previsão de resultado de cada jogo.
Então o primeiro passo é buscar esse HTML no site onde você tem a informação. No caso das informações dos jogos eu fui buscar no site tabeladobrasileirao.net.
Começo utilizando o requests do Python para retornar o HTML dos jogos e seus resultados (no caso dos que já aconteceram).
import requests
r = requests.get('http://www.tabeladobrasileirao.net/')
Depois é a vez do BeautifulSoup4 entrar em ação. Passo o resultado para o BS (com o encode) e ele “parseia” o HTML.
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text.encode('utf-8'), 'html.parser')
E aí começo a procurar. Depois de analisar o HTML do site, descubro onde as informações estão e uso o método find do BS para pegar as informações.
Neste código estou buscando a tabela com id igual a “jogos” e iterando sobre suas células, a partir das linhas da tabela. Como já identifiquei onde estão os dados, comecei a guardá-los em um dicionário (tratando datas, tipos e resultados nulos) que usarei para salvar no banco de dados posteriormente. Por exemplo, cada jogo está em uma linha e a data dele está na segunda coluna, então uso cells[1].find(text=true) para pegar somente o texto da célula.
Omiti a parte de salvar no banco de dados, mas o código todo está disponível no meu Github.
Com todos os jogos salvos é a vez de procurar pela previsão de resultados no Bing.
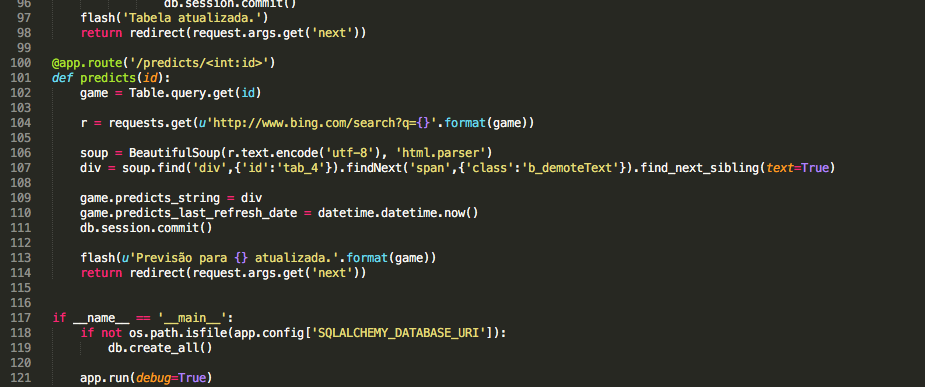
Mais uma vez começo com o requests e dou um parse no resultado com o BS. Leve em consideração que a variável “game” no código abaixo retorna a string com o jogo em questão, por exemplo, “Internacional x Grêmio” ou “Corinthians x Flamengo”.
r = requests.get(u'http://www.bing.com/search?q={}'.format(game))
soup = BeautifulSoup(r.text.encode('utf-8'), 'html.parser')
div = soup.find('div',{'id':'tab_4'}).findNext('span',{'class':'b_demoteText'}).find_next_sibling(text=True)
predicts_string = div
Nesse caso foi muito mais difícil achar o local exato no código fonte do resultado da busca do Bing do que foi no caso do tabeladobrasileirao.net. Mas com um pouco de pesquisa e muita tentativa e erro eu acabei chegando no texto de previsão do Bing usando soup.find(‘div’,{‘id’:’tab_4′}).findNext(‘span’,{‘class’:’b_demoteText’}).find_next_sibling(text=True), mais uma vez com text=true para retornar somente o texto do objeto que vem no formato “Chapecoense 14% – Empate 29% – Corinthians 57%”, por exemplo.
Com os templates do Flask eu criei um pequeno site que executa e exibe o resultado desses crawlers. Ficou assim:
Essa foi minha primeira experiência com BeautifulSoup4 e crawlers. Qualquer dúvida ou sugestão, deixe um comentário abaixo. E para ver o código fonte desse pequeno app acesse meu Github.
Em novembro de 2015 recebi uma ligação de uma empresa na qual eu já havia feito entrevistas e testes meses antes. Nesta ligação marcamos uma reunião e na próxima semana lá estava eu ouvindo pela primeira vez sobre o Diligeiro.
O Diligeiro é um aplicativo para smartphone que serve para conectar advogados correspondentes com escritórios de advocacia ou advogados que precisam do serviço de diligência.
O meu desafio era criar o backend desse aplicativo, uma API. O seu grande diferencial é a geolocalização, mostrar aos correspondentes quais diligências estão mais próximas dele. Ou seja, seria minha primeira experiência desenvolvendo uma API e também a primeira experiência com Geolocalização. Estudei, experimentei e hoje posso dizer que aprendi muito.
Enquanto ainda desenvolvia todas essas coisas novas para mim, fui escalado para fazer também o frontend web do mesmo produto. Mais uma série de aprendizados, desenvolver um frontend web totalmente baseado em requisições de API. Mais estudos, experiências e aprendizados.
Nas últimas semanas o aplicativo para Android e a versão Web do Diligeiro foram lançados em formato Alpha e em seguida em formato Beta, para que os usuários pudessem começar a utilizá-lo e passarem seus feedbacks.
Foram seis meses de muito trabalho, muitos aprendizados e também muita diversão, graças à equipe incrível da TIA Tikal.
O trabalho continua, as melhorias e novas ideias para funcionalidades não param nunca, mas a fase inicial de desenvolvimento acabou. Agora é hora de deixar que os usuários decidam se todo o esforço valeu a pena. O aplicativo iOS continua em desenvolvimento.
Me sinto orgulhoso pelo resultado dessa primeira fase e agradecido a todos os envolvidos. A equipe do Diligeiro e a equipe do LegalNote, o produto irmão do Diligeiro que já está no mercado a mais tempo.
Segue uma galeria com algumas peças criadas durante este ano para os websites do Grupo ETAPA de São Paulo e Valinhos, SP. Alguns para sites com acesso exclusivo e outros para os sites de área aberta.